无码av影片新闻
无码av影片 师生论文被国际学术会议NeurIPS 2025录用
日期:2025-09-24访问量:近日,中国计算机学会(CCF)推荐的A类国际学术会议NeurIPS 2025论文接收结果公布。无码av影片 师生有39篇论文被录用,其中 37 篇被 Main Track 录用(含2篇Oral论文)、2 篇被 Datasets and Benchmarks Track 录用。神经信息处理系统大会(Neural Information Processing Systems,简称NeurIPS)与国际机器学习大会(ICML)、国际学习表征会议(ICLR)并称“机器学习三大顶会”。据悉,第39届NeurIPS会议将于2025年12月2日至7日在美国圣地亚哥和墨西哥城两地同步举行。

Main Track
论文介绍
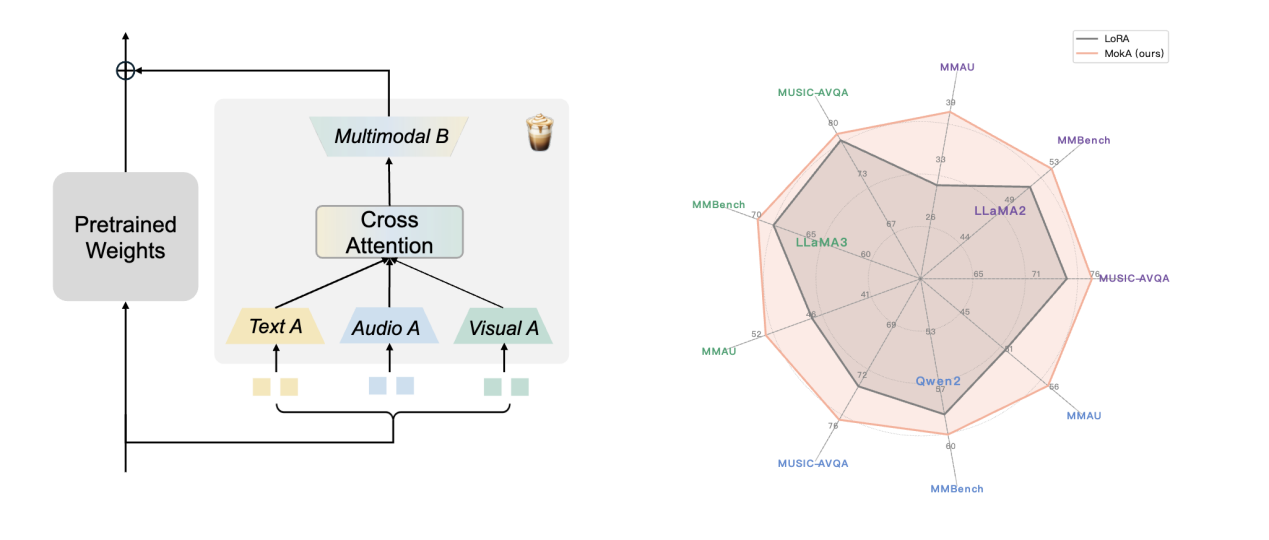
论文题目:MokA: Multimodal Low-Rank Adaptation for MLLMs (Oral)
作者:卫雅珂,苗雨,周东展,胡迪
通讯作者:胡迪
论文概述:当下,一般MLLMs微调方案大多简单的将单模态策略迁移至多模态场景,未结合多模态学习特性进行深入思考。我们认为多模态微调不仅需要考虑模态间交互,也需要考虑单模态特性。为此,在最近的工作中,我们以一种新的视角来反思多模态微调的基本逻辑,最终形成了简单高效的MokA微调方案,同时保证单模态与跨模态adaptation,更加适合多模态场景。MokA结合不同基座模型在多个多模态场景下都相比统一处理范式取得了更优的结果。
论文介绍
论文题目:Large Language Diffusion Models (Oral)
作者:聂燊*,朱峰琪*,游泽彬,张晓露,欧竞阳,胡俊,周俊,林衍凯,文继荣,李崇轩
通讯作者:李崇轩
论文概述:大语言模型的能力被普遍认为依赖于自回归模型。我们通过引入 LLaDA 来挑战这一观点,LLaDA 是一种在预训练和监督微调范式下从头开始训练的扩散模型。LLaDA 采用前向数据掩码过程和反向生成过程,由 Transformer 进行参数化以预测被掩码的词元。它通过优化似然下界为概率推理提供了一种原则性的生成方法。在通用任务、数学、代码等广泛的基准测试中,LLaDA 展示了强大的可扩展性,并且性能与我们自己构建的自回归模型基线相当。值得注意的是,LLaDA 8B 在上下文学习方面与 LLaMA3 8B 等强大的大语言模型具有竞争力,并且在监督微调之后,在多轮对话等案例研究中展现出令人印象深刻的指令遵循能力。此外,LLaDA 解决了反转诅咒问题,在反转诗歌补全任务中超越了 GPT-4o。我们的研究结果表明,扩散模型在大规模语言建模方面具有前景,并挑战了上述核心大语言模型能力固有地依赖于自回归模型的普遍假设。
论文介绍
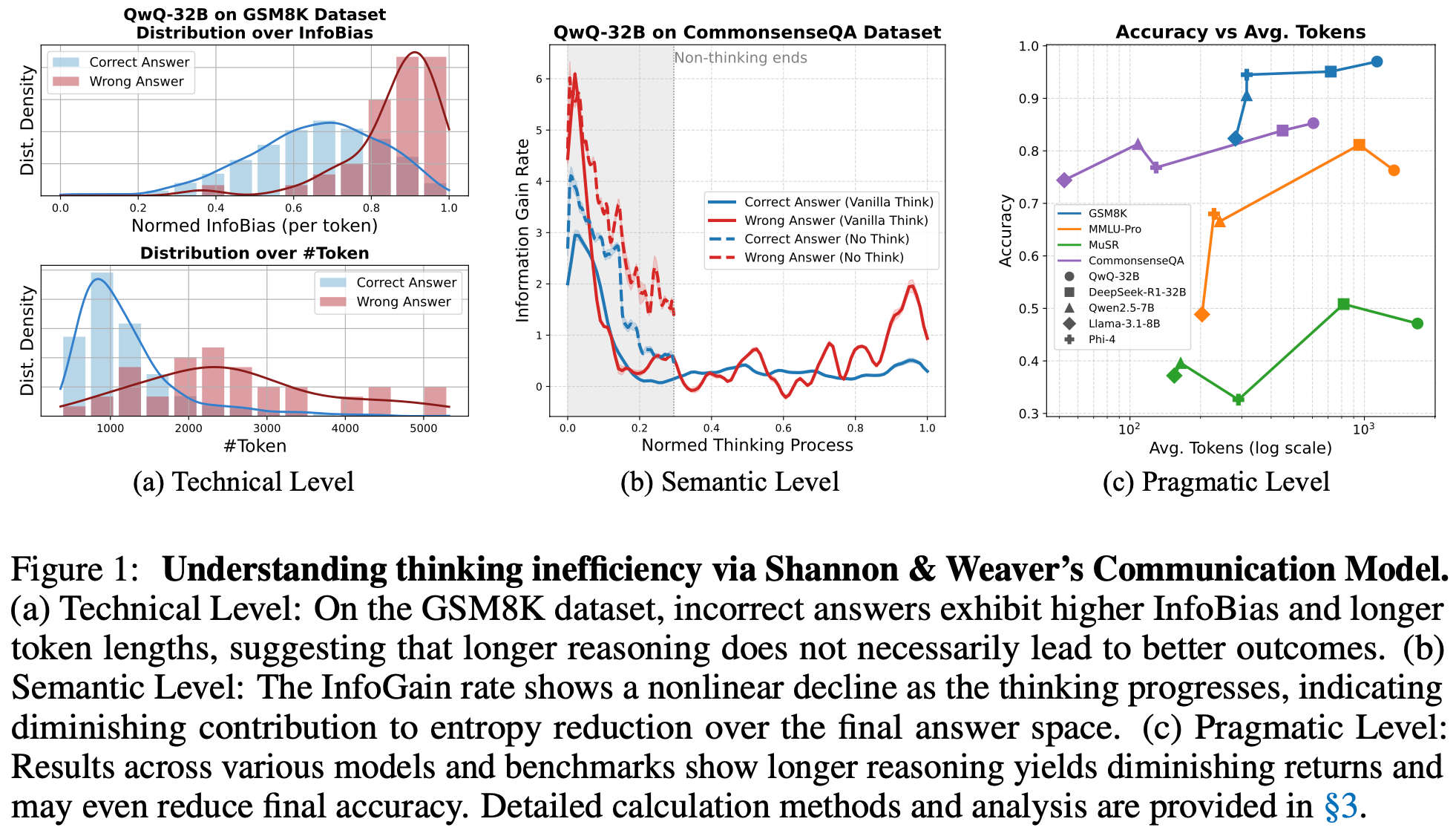
论文题目:Think or Not? Exploring Thinking Efficiency in Large Reasoning Models via an Information-Theoretic Lens
作者:雍希贤,周骁,张莹莹,李锦林,郑冶枫,吴贤
通讯作者:周骁,吴贤
论文概述:大型推理模型(Large Reasoning Models)的兴起极大提升了多步推理能力,但也伴随着冗长推理链条的问题。本文从信息论视角重新审视推理效率,提出了两个核心度量指标——信息偏差(InfoBias)与信息增益(InfoGain),分别用于衡量推理路径的理想性偏离与逐步的信息贡献。实证分析发现,较长的推理链往往存在更高的信息偏差和递减的信息增益,尤其在错误答案中更为显著。基于这一观察,我们提出了一种基于熵的自适应推理策略(Adaptive Think),通过在模型置信度达到阈值时动态停止推理,以提升效率并保持准确性。实验结果表明,与默认的推理模式相比,该方法在QwQ-32B模型的六项不同类型与难度的推理任务中,实现了平均准确率提升1.10%,同时减少50.80%的token开销。这些结果展示了基于熵的方法在提升大模型推理效率与降低成本方面的潜力。
论文介绍
论文题目:Beyond Last-Click: An Optimal Mechanism for Ad Attribution
作者:安楠,李维安,祁琦,余昌远,张梁
通讯作者:祁琦
论文概述:本研究围绕在线广告归因展开,针对业界普遍采用的最后点击归因机制(Last-Click Mechanism, LCM)在准确性与公平性方面的不足进行了系统性分析。结果表明,LCM并不满足占优策略激励相容性要求,且在异质平台环境下可能导致准确率和公平性显著下降。为克服这一局限,提出了一种新的同伴验证机制(Peer-Validated Mechanism, PVM),其归因结果依赖于其他平台的报告与先验概率,而不受平台自身报告影响,从而在机制设计上实现了激励相容性。理论证明显示,PVM在同质平台环境下能够达到最优准确性,在异质环境中亦具备严格的性能保证,并在公平性方面确保归因分配与平台真实贡献概率完全一致。基于真实广告数据的数值实验进一步验证了PVM在准确性与公平性上均显著优于LCM。本研究首次从机制设计的视角建立广告归因的理论框架,为发展公平、稳健且激励兼容的数字广告归因系统提供了新的方法与启示。


论文介绍
论文题目:Universally Invariant Learning in Equivariant GNNs
作者:岑嘉诚,李安亿,林宁,徐挺洋,荣钰,赵德丽,王子贺,黄文炳
通讯作者:黄文炳
论文概述:等变图神经网络(Equivariant Graph Neural Networks, GNNs)在多种应用中已展现出显著成功。为了实现完备性——即在等变函数空间上的通用逼近性质——网络必须能够有效捕捉不同节点之间复杂的多体相互作用。以往的方法通常通过加深网络结构、提高交互阶数或增加可导向特征的维度来实现,但往往伴随着巨大的计算开销,且缺乏多项式时间的解法。在本文中,我们提出了一个具有坚实理论基础的框架,用于构建既高效又实用的完备等变图神经网络。我们证明了:只需两个关键组成部分就能实现完备的等变图神经网络——1)一个完备的标量函数,被称为几何图的标准型;2) 一个满秩的可操控基集合。基于这一发现,我们提出了一种高效算法,能够利用两类常见模型(EGNN 和 TFN)来构建完备的等变图神经网络。实验结果表明,我们的模型在仅使用少量层数的情况下,便能实现更强的完备性与优异的性能,从而显著降低计算开销,同时保持良好的实用效果。

论文介绍
论文题目:FlexWorld: Progressively Expanding 3D Scenes for Flexible-View Exploration
作者:陈路晰*,周子晗*,赵敏,王一凯,张舸,黄文灏,孙浩,文继荣,李崇轩
通讯作者:李崇轩,王一凯
论文概述:本文介绍了FlexWorld,这是一个从单张图像生成灵活视角3D场景的框架。它结合了一个微调的视频到视频扩散模型,用于高质量的新视角合成,以及一个渐进的灵活视角3D场景生成过程。通过利用先进的预训练视频基础模型和精确的训练数据,FlexWorld能够处理大幅度的相机姿态变化,从而实现一致的、支持360°旋转和前进后退观察的3D场景生成。大量实验表明,与现有方法相比,FlexWorld在视角灵活性和视觉质量性能方面表现优异。我们相信FlexWorld具有广阔的前景,并在虚拟现实内容创作和3D旅游领域具有重要潜力。
论文介绍
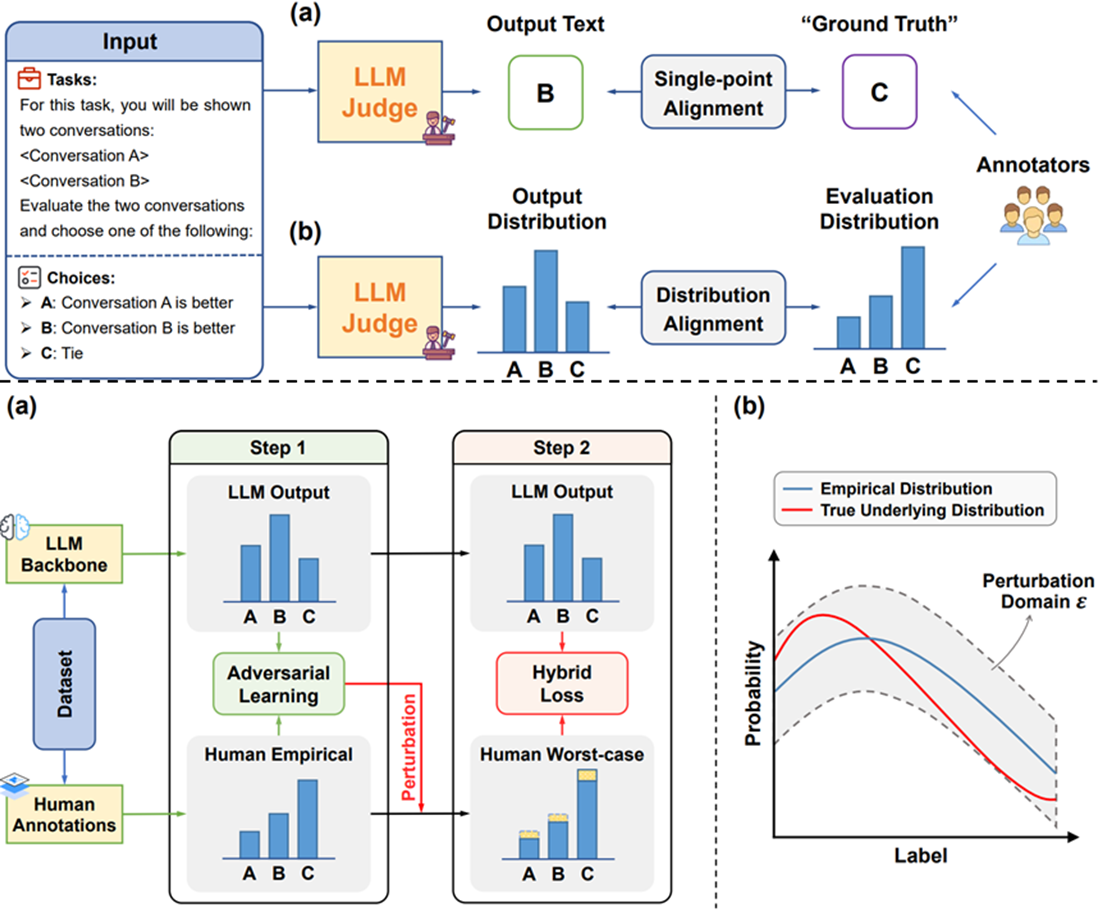
论文题目:Beyond Single-Point Judgment: Distribution Alignment for LLM-as-a-Judge
作者:陈麓羽,张泽宇,谭浩然,戴全宇,杨镐,董振华,陈旭
通讯作者:陈旭
论文概述:传统的LLM-as-a-Judge倾向于给出一个单一的评估结果,例如为一段文本评定一个绝对分数,但这与真实人类评估中所蕴含的丰富多样性与不确定性相悖(不同评估者可能会给出不同的打分)。这种简化处理削弱了评估结果的可靠性。为解决此问题,本研究开创性地提出了一个新颖的训练对齐框架,旨在将LLM生成的评估结果的分布与真实的人类评估的分布进行显式对齐。我们的核心方法是设计一个基于KL散度的分布对齐目标函数,并辅以交叉熵正则化来稳定训练过程。此外,考虑到实际应用中人类标注数据可能有限或存在噪声,我们进一步引入了对抗训练来提升模型在分布对齐过程中的鲁棒性。实验结果表明,在多种模型和评估任务上,我们的框架在对齐质量、评估准确性和鲁棒性方面均显著优于现有的闭源大语言模型以及传统的单点对齐方法。
论文介绍
论文题目:Masked Diffusion Models as Energy Minimization
作者:陈思同,聂燊,孙嘉城,冯子晋,李震国,文继荣,李崇轩
通讯作者:李崇轩
论文概述:我们提出了一个系统性的理论框架,将掩码扩散模型(MDMs)阐释为离散最优传输中能量最小化问题的求解方案。具体而言,我们证明了在MDMs的结构框架下,三种不同的能量形式——动能、条件动能与测地能量——具有数学等价性,且当掩码调度满足闭式最优条件时,MDMs能够同时最小化这三种能量。这一理论统一不仅厘清了MDMs的理论基础,还为采样过程的实践改进提供了理论动机。通过采用Beta分布对插值调度进行参数化,我们将调度设计空间压缩至可处理的二维搜索问题,从而无需修改模型即可实现高效的训练后调优。在合成数据集与真实基准测试上的实验表明,我们基于能量原理设计的调度策略优于人工设计的基线方法,尤其在低步数采样场景中表现显著。
论文介绍
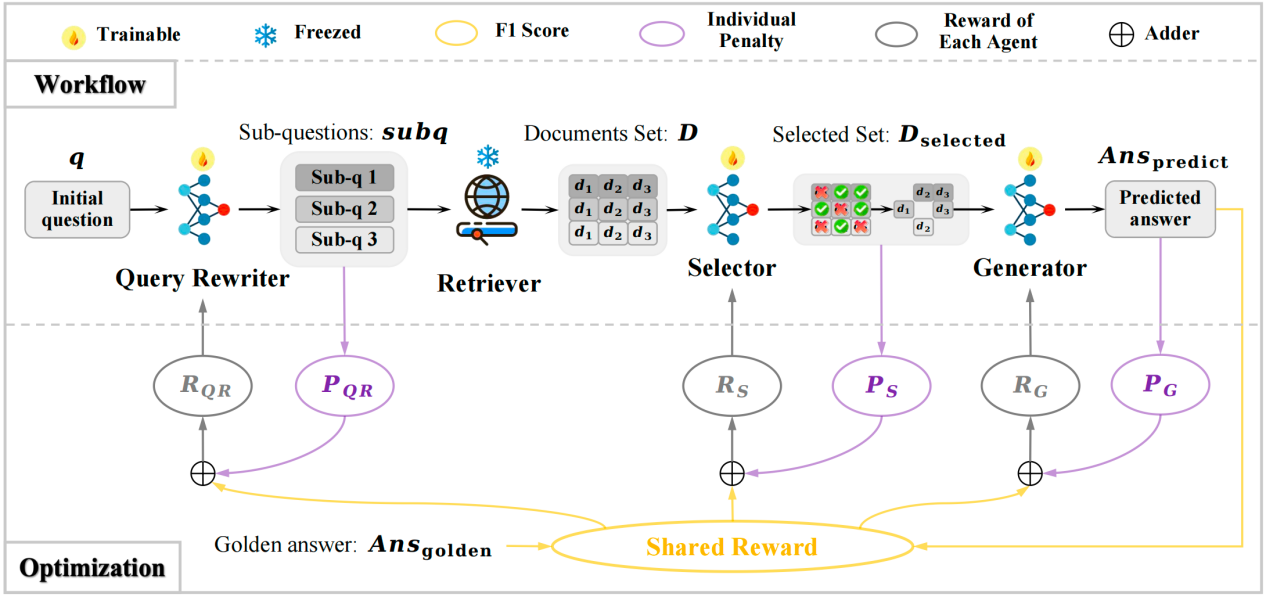
论文题目:Improving Retrieval-Augmented Generation through Multi-Agent Reinforcement Learning
作者:陈逸群,颜令勇,孙维纬,马新宇,张艺,王帅强,殷大伟,Yiming Yang,毛佳昕
通讯作者:毛佳昕
论文概述:《Improving Retrieval-Augmented Generation through Multi-Agent Reinforcement Learning》这篇论文针对当前Modular RAG系统中各模块通常独立优化导致优化目标不一致的问题,提出了一种基于多智能体强化学习的多模块联合优化框架 MMOA-RAG。在此框架中,我们将系统中的多个模块视为完全合作的智能体,从而将RAG系统建模为了完全合作式的多智能体协作任务。我们通过 Multi-Agent PPO 算法实现多模块协同训练,使用共享的最终答案质量(如 F1 分数)作为全局奖励。实验表明该方法在多个问答数据集上显著优于现有baselines,验证了多模块协同优化在提升 RAG 系统性能上的关键作用。
论文介绍
论文题目:Incentivizing Dual Process Thinking for Efficient Large Language Model Reasoning
作者:成晓雪*,李军毅*,张振铎,汤昕宇,赵鑫,孔心宇,张志强
通讯作者:赵鑫
论文概述:大语言模型在复杂推理任务上表现,却常常在简单任务中因“过度思考”而生成冗余内容。受认知科学中双过程理论启发,我们提出自适应认知策略优化(ACPO)——一种强化学习框架,使语言模型通过自适应认知分配与动态系统切换实现高效推理。ACPO 包含两大核心组件:(1)引入“系统感知推理token”,显式表征思考模式,让模型的认知过程透明化;(2)融合在线难度估计与token长度预算,在强化学习过程中指导自适应系统切换与推理。为此,我们设计了两阶段训练策略:第一阶段以监督微调冷启动模型,使其生成带显式思考模式的推理路径;第二阶段应用 ACPO,进一步强化面向难度的自适应系统切换。实验结果表明,ACPO 能显著减少冗余推理,并依据任务复杂度自适应调节认知分配,实现高效的混合推理。
论文介绍
论文题目:UniGist: Towards General and Hardware-aligned Sequence-level Long Context Compression
作者:邓琛龙,张智松,毛科龙,李帅谊,方天庆,张洪铭,米海涛,俞栋,窦志成
通讯作者:张智松,窦志成
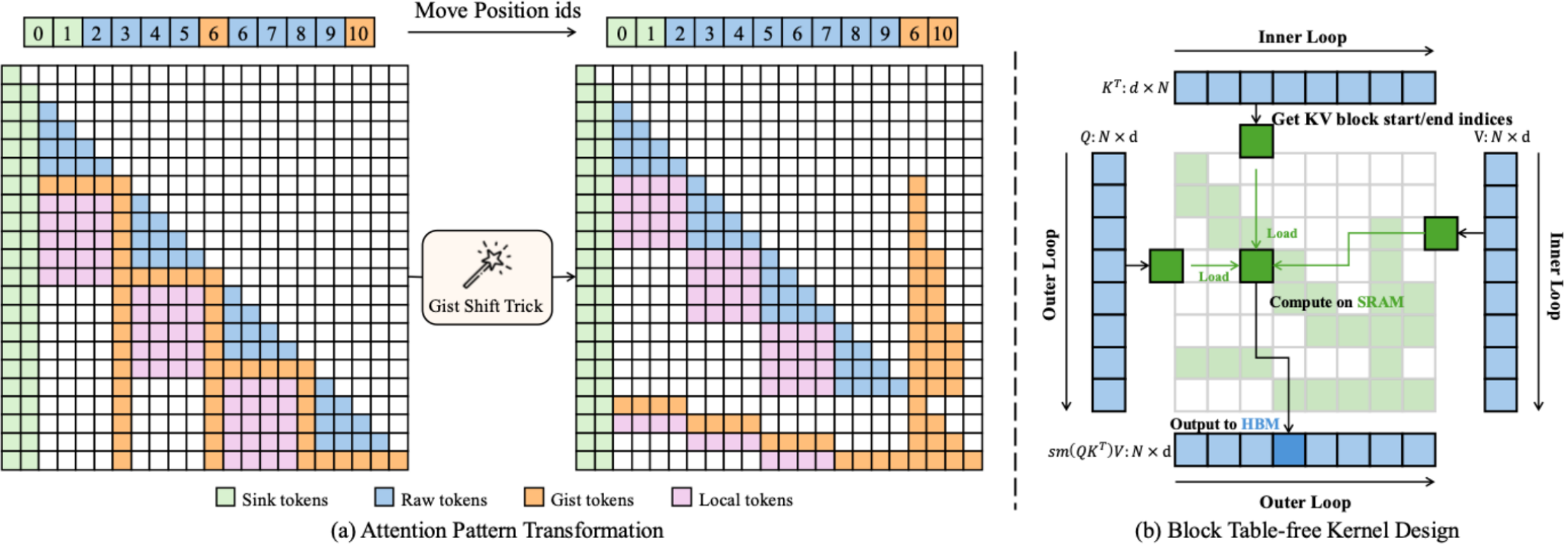
论文概述:大语言模型在处理长上下文输入方面的能力日益增强,但KV缓存的内存开销仍然是通用部署的主要瓶颈。虽然许多压缩策略已经被探索过,但其中的Token序列级压缩由于容易丢失重要细节而特别具有挑战性。我们提出了UniGist,这是一个基于Gist Token的长上下文压缩框架,它消除了对分块训练的需求,使模型能够在训练过程中学习如何压缩和利用长距离上下文。为了充分利用稀疏性,我们引入了一种Gist Shift技巧,将注意力布局转换为右对齐的块结构,并基于此开发了一个无需块表的稀疏注意力内核。UniGist进一步支持单次训练和推理过程中灵活的分块大小,实现了高效且自适应的上下文处理。在多个长上下文任务上的实验表明,UniGist显著提高了压缩质量,在细节召回和长距离依赖建模方面表现尤为出色。
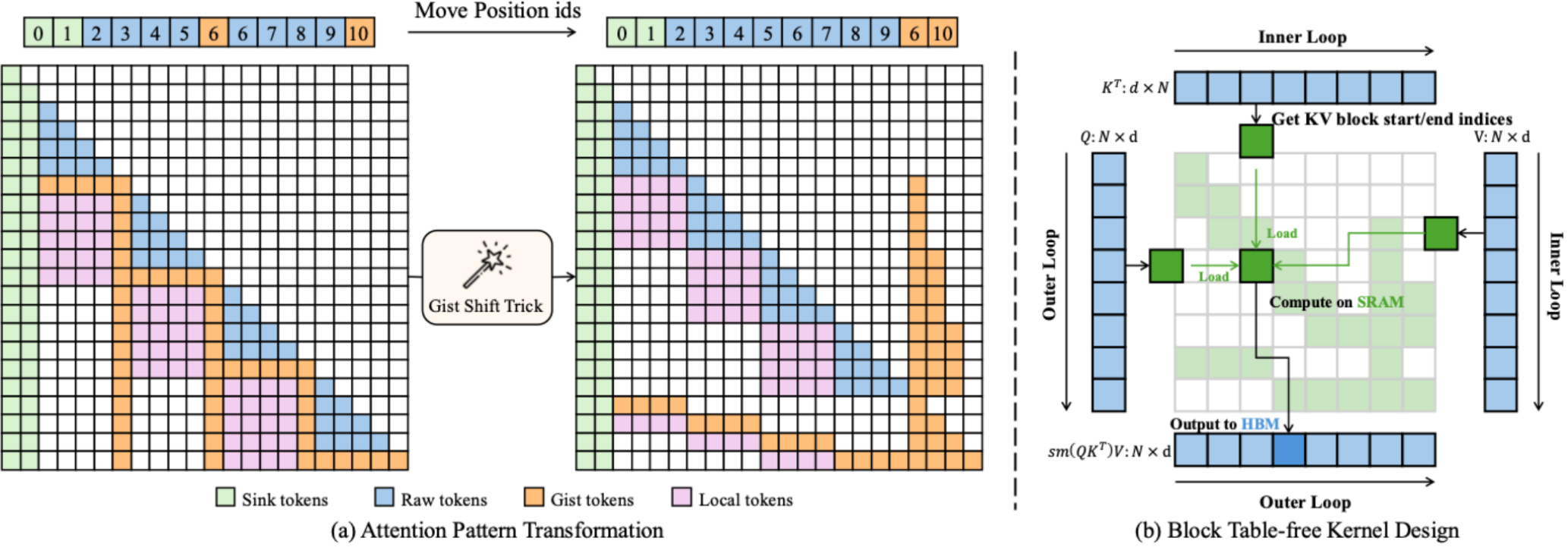
论文介绍
论文题目:Domain Specific Pruning of Large Mixture-of-Experts Models with Few-shot Demonstrations
作者:董梓灿*,彭涵*,刘沛羽,赵鑫,吴东,肖锋,王志峰
通讯作者:刘沛羽,赵鑫
论文概述:混合专家模型 (MoE) 通过仅激活部分专家,实现了性能与推理效率之间的良好平衡。然而,存储所有专家带来的内存开销仍然是一个主要限制,尤其是在像 DeepSeek-R1 (671B) 这样的超大规模 MoE 模型中。在本研究中,我们探讨了大规模 MoE 模型中的领域专化与专家冗余问题,并发现了一种一致的现象,我们称之为 少样本专家定位:只需少量同领域的示例,模型便能在该领域任务中稳定且稀疏地激活一小部分专家。基于这一观察,我们提出了一种简单而有效的剪枝框架 EASY-EP,它利用少量领域特定的示例来识别并保留最相关的专家。EASY-EP 包含两个关键组件:(1)输出感知的专家重要性评估:通过结合门控分数与已激活专家输出的 L2 范数来评估当前 token 中每个专家的重要性。(2)专家级 token 贡献估计:通过比较路由前后表示的相似性来评估 token 的贡献度。在 DeepSeek-R1 和 DeepSeek-V3-0324 上的实验表明,在相同的内存预算下,我们的方法只需保留一半的专家,便能在性能和吞吐量上达到与完整模型相当的水平。
论文介绍
论文题目:Generalizing Experience for Language Agents with Hierarchical MetaFlows
作者:樊昇达,从鑫,张众,傅岳朋,吴叶赛,王豪,张鑫宇,胡恩瑞,林衍凯
通讯作者:林衍凯
论文概述:近期将大语言模型用作智能体的研究工作在广泛的任务中展现出了令人瞩目的成果。然而,现有智能体缺乏有效的经验复用方法来充分利用历史已完成任务的经验。我们提出了一种新颖的经验复用框架 MetaFlowLLM,该框架从历史已完成任务中构建层次化经验树。该经验树中的每个节点都表示为一个 MetaFlow,包含静态执行工作流和智能体动态完成任务所需的子任务。然后,我们提出了层次化MetaFlow合并算法来构建层次化经验树。在完成新任务时,MetaFlowLLM 能够首先从经验树中检索最相关的 MetaFlow 节点,然后据此执行。为了从历史数据中有效生成有效的 MetaFlows,我们进一步提出了强化学习流水线来训练 MetaFlowGen。在 AppWorld 和 WorkBench 上的大量实验结果表明,集成 MetaFlowLLM 后,现有智能体(如 ReAct、Reflexion)能够获得显著的性能提升,同时降低执行成本。值得注意的是,MetaFlowLLM 在 AppWorld 上实现了平均 32.3% 的成功率提升,在 WorkBench 上实现了 6.2% 的成功率提升。
论文介绍
论文题目:Learning to Focus: Causal Attention Distillation via Gradient-Guided Token Pruning
作者:郭一驹,杨文恺,孙泽旭,丁宁,刘知远,林衍凯
通讯作者:林衍凯
论文概述:尽管大语言模型在自然语言处理任务中展现出强大的上下文理解与生成能力,但在长文本推理与复杂指令任务中仍存在注意力分散、难以聚焦关键信息的问题,从而制约了推理准确性与生成质量。我们的实验发现,仅删除输入中的干扰模式(distracting patterns),Llama 与 Qwen 系列小模型在数学和代码任务上的准确率即可分别提升 20% 与 10%,说明推理失败往往源于注意力偏移而非能力不足。为此,我们提出基于因果视角的 LeaF(Learning to Focus)框架,将干扰信息视为虚假混杂因素,通过两阶段机制加以缓解:首先利用教师—学生梯度对比识别并剪除confounding tokens 构建反事实样本;随后在蒸馏阶段通过混合蒸馏损失函数同时对原始样本与反事实样本最小化 KL 散度,从而引导学生模型学习更加稳健且具有因果解释性的注意力模式。实验表明,LeaF 在数学推理(GSM8K、MATH、OlympiadBench)、代码生成(HumanEval+、LeetCode、LivecodeBench)及 RAG(2Wikimqa、Musique、HotpotQA)任务上均实现 2–4% 的平均提升,并显著增强了模型对关键信息的聚焦能力,从而实现更可靠、可解释的推理。
论文介绍
论文题目:Geometric Mixture Models for Electrolyte Conductivity Prediction
作者:李安亿,岑嘉诚,李松佑,李明泽,于洋,黄文炳
通讯作者:黄文炳
论文概述:准确预测电解质体系中的离子电导率,对于推动众多科学与技术应用的发展至关重要。尽管已有显著进展,当前研究仍面临两大根本性挑战:(1)缺乏高质量的标准化基准数据集;(2)对混合体系中分子几何结构及分子间相互作用的建模不足。为解决这些问题,我们首先重新整理并改进了CALiSol和DiffMix两个电解质数据集,通过引入分子的几何图表示来增强其信息表达。随后,我们提出了GeoMix——一种新颖的、具备几何感知能力的框架,该框架保持了Set-SE(3)等变性,这一特性在混合体系建模中至关重要但实现难度较高。GeoMix的核心是几何交互网络,这是一种专为分子间几何信息传递设计的等变模块。大量实验表明,GeoMix在两个数据集上均优于多种基线模型,验证了跨分子几何相互作用和等变信息传递在准确预测体系性质方面的重要性。本研究不仅为电解液研究建立了新的基准,还提供了一个通用的几何学习框架,有望推动能源材料、药物研发等领域中混合体系的建模。
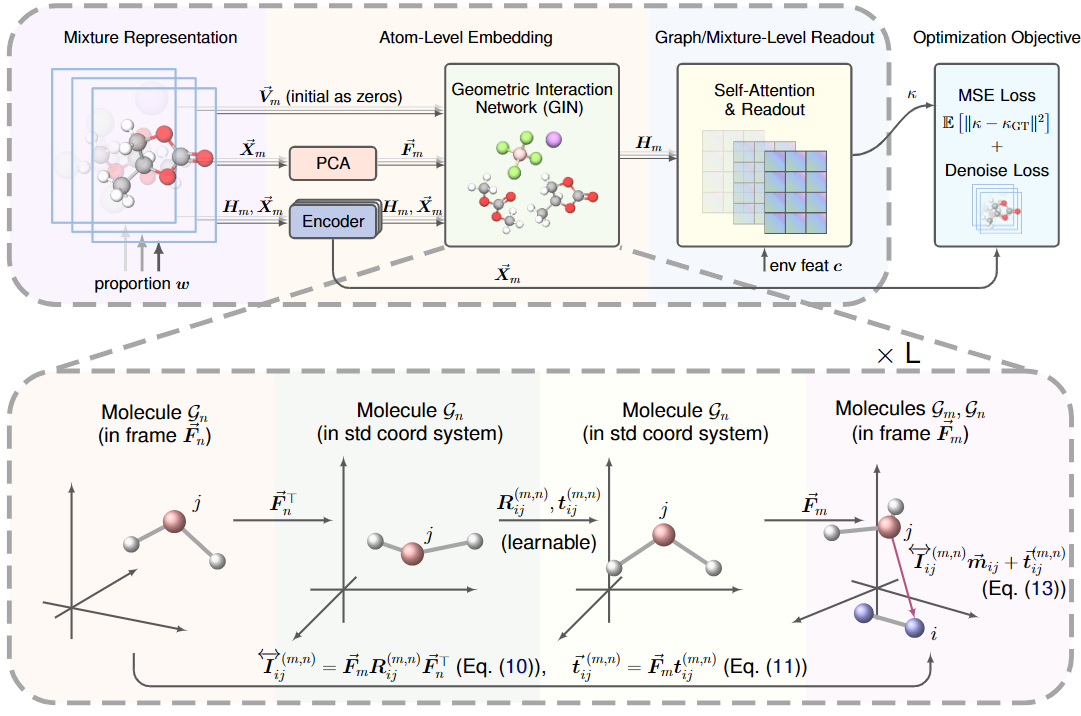
论文介绍
论文题目:CAM: A Constructivist View of Agentic Memory for LLM-Based Reading Comprehension
作者:李锐,戴全宇,张泽宇,薄小荷,田子杭,陈旭,董振华,唐睿明
通讯作者:陈旭
论文概述:当前大语言模型在长文本理解中面临着信息过载的挑战,这凸显出构建一个内在记忆模块的必要性,以将通用大语言模型升级为具备自主阅读能力的智能体。尽管已有若干启发式尝试,但仍缺乏系统化的设计原则。为此,本文借鉴让·皮亚杰的建构主义理论,提炼出智能体记忆的三项核心特征:结构化图式、灵活同化与动态顺应。这一设计蓝图为打造更加稳健且高效的大语言模型记忆系统提供了清晰路径。基于这些原则,本文进一步提出了建构主义智能体记忆的原型实现CAM,其兼具结构性、灵活性与动态性三重特征。CAM的核心是一种增量式重叠聚类算法,既支持连贯的层次化摘要总结,也支持在线批量整合新信息。在推理阶段,CAM自适应地探索记忆结构,激活与输入查询相关的信息以生成上下文响应,类似于人类的联想机制。与现有方法相比,CAM在多种长文本阅读理解任务上同时展现出性能与效率的双重优势,包括问答,查询总结和论断验证。
论文介绍
论文题目:WebThinker: Empowering Large Reasoning Models with Deep Research Capability
作者:李晓熙,金佳杰,董冠霆,钱泓锦,朱余韬,伍永康,文继荣,窦志成
通讯作者:窦志成
论文概述:大型推理模型(如OpenAI-o1和DeepSeek-R1)在长程推理任务中展现出卓越的能力,但其性能受限于对静态内部知识的依赖,尤其在处理复杂知识密集型任务或生成需综合多源网络信息的全面研究报告时表现不足。针对这一问题,本文提出WebThinker——一种具备深度研究能力的智能体系统,能够在推理过程中自主边思考、边搜索、边写作,来端到端完成一整个研究任务。该系统集成了“深度网络探索器”模块,使模型能够动态检索、遍历和提取网络信息以弥补知识缺失;同时采用“自主思考-搜索-起草”策略,实现推理、信息获取与报告撰写的无缝协同。为进一步优化研究工具的使用效果,我们还提出一种基于强化学习的训练策略,通过迭代式在线直接偏好优化(DPO)提升模型对工具的调用能力。在多个复杂推理基准(包括GPQA、GAIA、WebWalkerQA和HLE)以及科学报告生成任务(Glaive)上的实验表明,WebThinker显著优于现有方法及主流闭源系统,有效提升了推理模型在复杂场景下的可靠性,为构建更强大、更通用的深度研究系统奠定了基础。相关代码已开源://github.com/RUC-NLPIR/WebThinker。

论文介绍
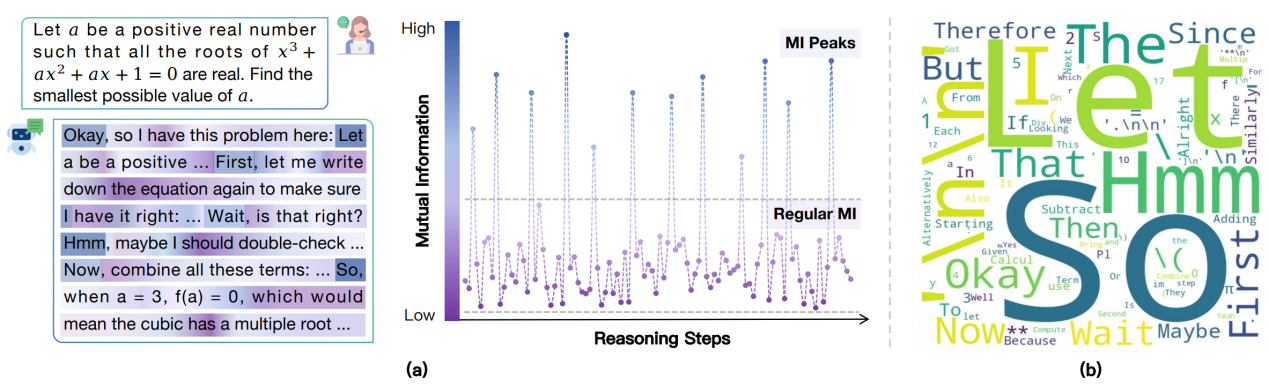
论文题目:Demystifying Reasoning Dynamics with Mutual Information: Thinking Tokens are Information Peaks in LLM Reasoning
作者:钱辰, 刘东瑞, 温昊辰, 白振, 刘勇, 邵婧
通讯作者:刘勇, 邵婧
论文概述:大型推理模型(Large Reasoning Models, LRM)在复杂问题求解中展现出了令人惊叹的能力,但其内部推理机制依然知之甚少。本文从信息论的角度出发,研究了 LRM 的推理轨迹。我们发现,在模型的推理过程中,表示与正确答案之间的互信息(Mutual Information, MI)会在某些生成步骤中出现突增现象。理论分析表明,MI 的提升往往伴随着预测错误概率的降低。更有趣的是,这些 MI 峰值常常对应一些反思或转折类的词,例如 “Hmm”“Wait”“Therefore”,我们称之为思考型 Token。进一步实验证明,这些思考型 Token 对 LRM 的推理表现至关重要,而其他 Token 的影响则相对较小。基于这一发现,作者提出了两种简单但有效的方法,通过巧妙利用思考型 Token 来提升模型推理能力。总体而言,这项工作不仅为理解 LRM 的推理机制提供了新的视角,也为增强其推理性能提供了实用方案。
论文介绍
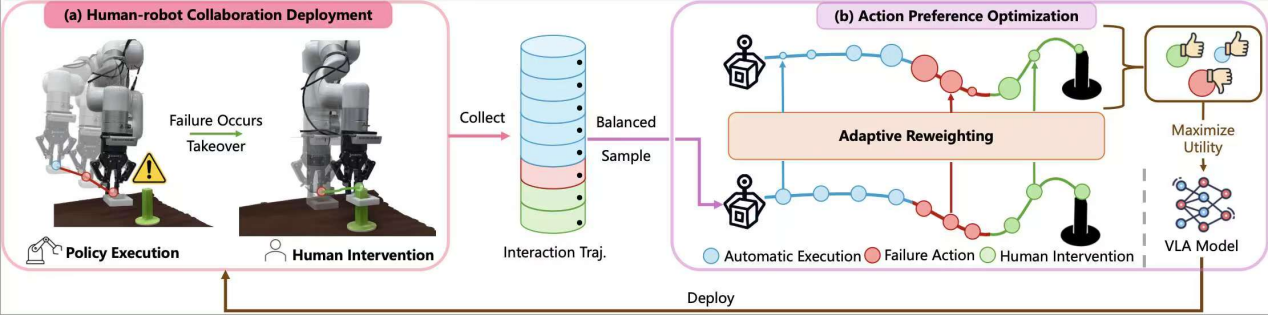
论文题目:Robotic Policy Learning via Human-assisted Action Preference Optimization
作者:夏文科,杨逸初,吴洪涛,马晓,孔涛,胡迪
通讯作者:胡迪
论文概述:尽管多模态大模型与大规模预训练数据显著提升了机器人的感知决策与泛化能力,但现有的VLA模型在执行下游精细操作任务时,成功率仍难以满足实际应用的需求。与其在预训练阶段继续提升模型的通用性,我们更关注于部署后的学习:我们旨在构建一个通用算法框架,使VLA模型能够在环境中进行可靠交互,并从交互数据中进行迭代式优化。基于此出发点,我们首次将人机协同与动作级别的偏好学习矫正结合,使得模型通过少量环境交互与人工矫错即可实现下游任务快速适配与动作矫正。
论文介绍
论文题目:Towards Thinking-Optimal Scaling of Test-Time Compute for LLM Reasoning
作者:杨文恺,马树铭,林衍凯,韦福如
通讯作者:林衍凯
论文概述:近期研究表明,让模型用更长的思维链投入更多推理时间,可以显著提升其在复杂推理任务上的表现。当前研究大多聚焦于通过不断延长大语言模型(LLMs)的思维链长度来提升测试时计算量并探索其潜在收益。然而,我们关心这种趋势背后可能隐藏的问题:过度延长思维链长度是否会反而损害模型的推理能力?我们在数学推理任务上的探索揭示了一个出乎意料的发现:在某些领域中,过长的思维链确实可能削弱 LLM 的推理表现。进一步研究发现,不同领域中存在一个最佳的思维链长度分布,该分布在不同任务中并不相同。基于这一观察,我们提出了一种思维链最优扩展策略。该方法首先利用一小部分具有不同回答长度分布的种子数据,教会模型在深度思考时采用不同程度的推理代价。随后,模型在全量问题上选择其在不同推理代价下的最短正确回答,实现更高效、更有效的自我改进。
论文介绍
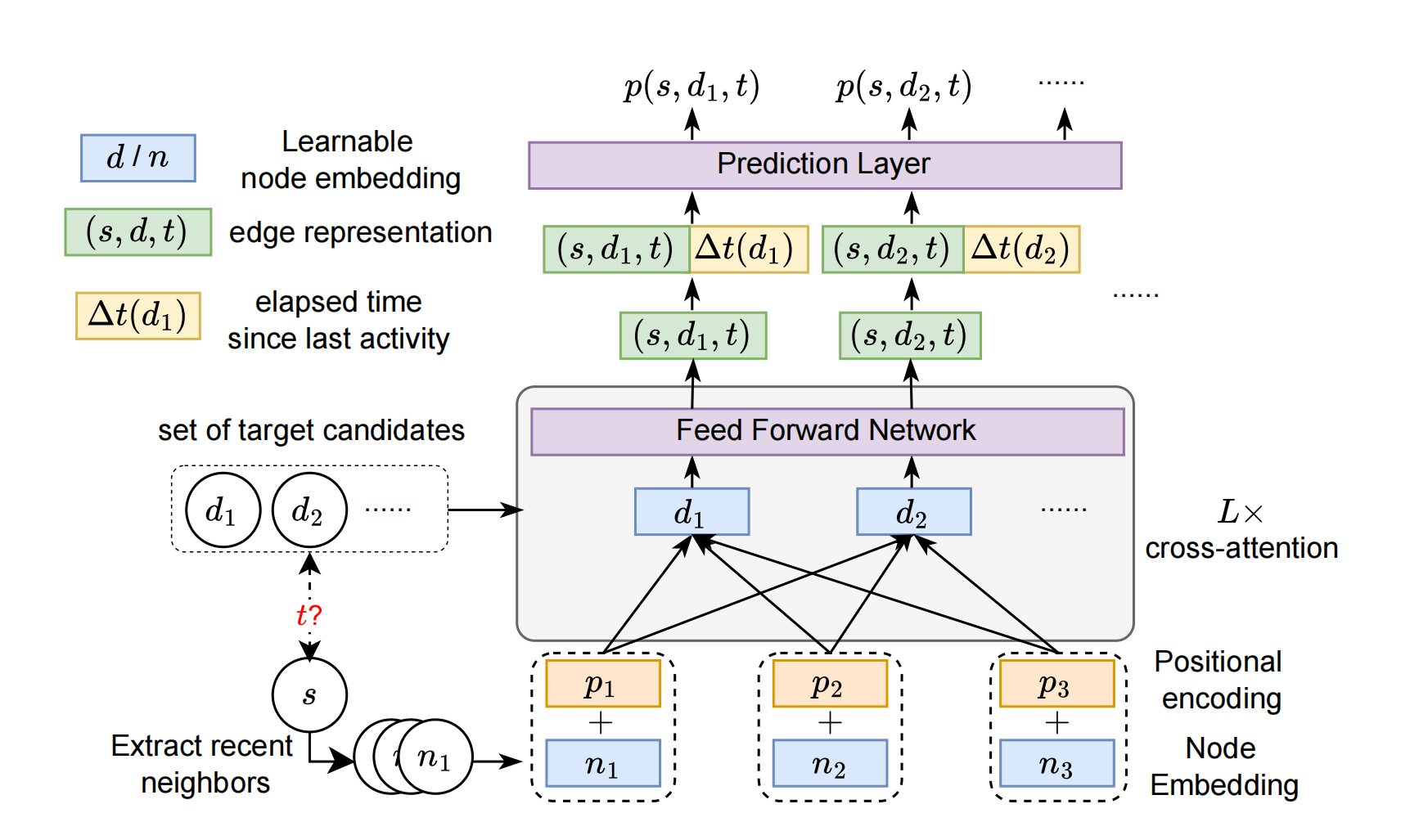
论文题目:Future Link Prediction Without Memory or Aggregation
作者:易璐,雷润林,莫冯然,郑艳萍,魏哲巍,叶宇航
通讯作者:郑艳萍,魏哲巍
论文概述:本研究围绕时序图中的未来链接预测问题展开,该任务在诸多动态系统中具有重要应用价值。现实场景中常同时包含重复出现的(已见)与新颖的(未见)交互关系,这对模型的泛化能力提出了更高要求。然而,现有方法普遍依赖复杂的记忆与聚合模块,难以有效处理未见边的预测问题。针对这一挑战,我们重新审视了当前时序图模型的架构,提出未来链接预测中两个被忽视但至关重要的建模需求:一是以唯一标识符表征节点,二是执行源节点与候选目标节点之间的目标感知匹配机制。在此基础上,我们提出了一种基于交叉注意力机制的时序图未来链接预测方法CRAFT(Cross-Attention based Future Link Predictor on Temporal Graphs)。该方法舍弃了传统的记忆与聚合结构,仅由两个核心组件构成:可学习的节点嵌入表示,以及目标节点与源节点近期交互之间的交叉注意力机制。CRAFT架构不仅具有较强的表达能力,还实现了基于交互模式的目标感知建模。在多个真实数据集上的实验结果表明,CRAFT在保持高效性的同时,取得了显著优于现有方法的预测性能,显示出其在大规模应用场景中的广泛适用性。
论文介绍
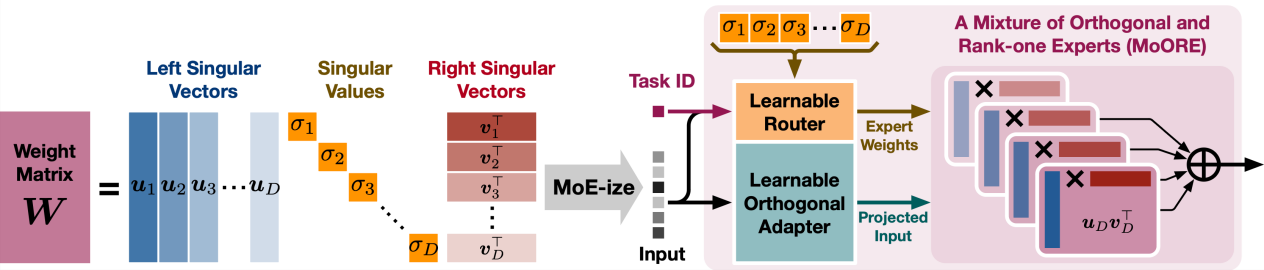
论文题目:MoORE: SVD-based Model MoE-ization for Conflict- and Oblivion-Resistant Multi-Task Adaptation
作者:袁深,郑胤,王太峰,刘彬彬,许洪腾
通讯作者:许洪腾
论文概述:针对大规模基础模型在多任务适配过程中常见的任务冲突与遗忘问题,提出了全新的“模型MoE化”策略——MoORE。该方法通过对预训练模型的权重矩阵进行SVD分解,并引入可学习的路由器,根据具体任务和样本动态调整奇异值,实现更加灵活和高效的多任务适配。MoORE将权重矩阵重构为一组正交Rank-one Experts的混合体,每个专家由左、右奇异向量的外积构成,并可通过可学习的正交变换提升模型容量。与传统的低秩适配方法(如LoRA)及其MoE变体相比,MoORE不仅保证了专家之间的正交性,还能保持原始权重矩阵的列空间,这两点分别有效缓解了新任务间的冲突和原任务的遗忘。训练过程中,MoORE利用可学习路由器在任务和样本层面动态分配专家权重,使模型能够在多任务场景下灵活适应不同任务需求,提升整体泛化能力。在常识推理、自然语言理解等多任务数据集上的实验结果表明,MoORE在抗冲突和抗遗忘方面均显著优于现有多任务适配方法,展现出卓越的性能和广泛的应用前景。
论文介绍
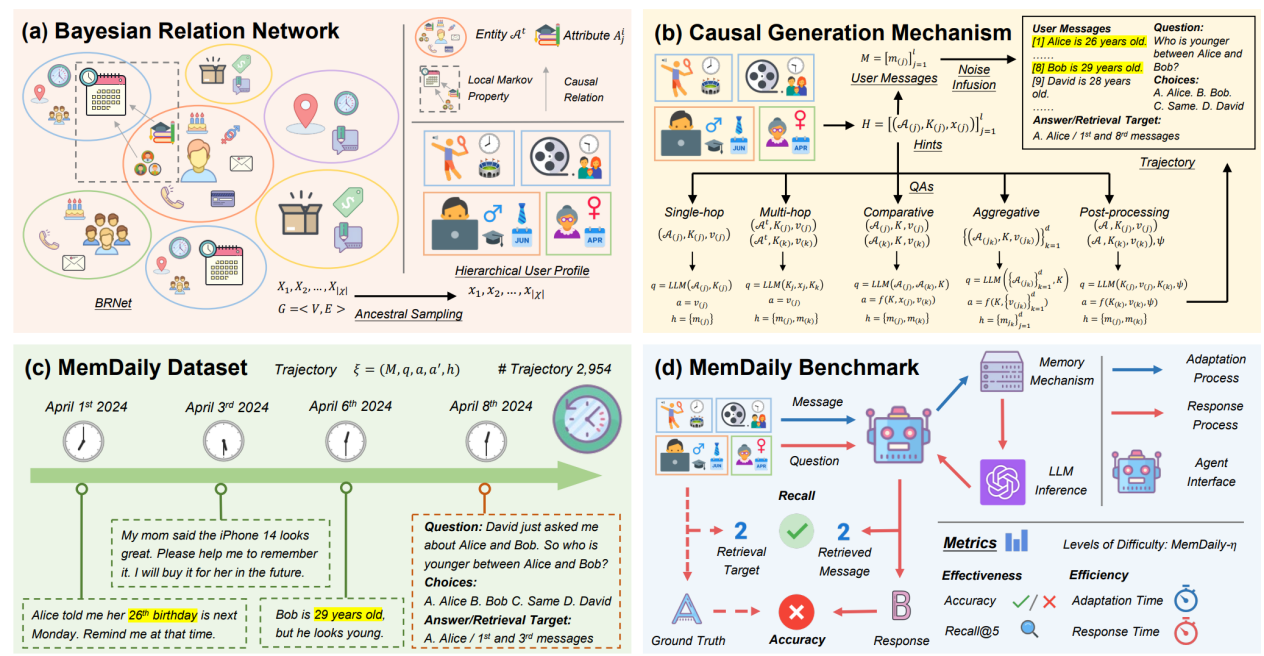
论文题目:MemSim: A Bayesian Simulator for Evaluating Memory of LLM-based Personal Assistants
作者:张泽宇,戴全宇,陈麓羽,姜泽仁,李锐,朱杰明,陈旭,谢奕,董振华,文继荣
通讯作者:陈旭
论文概述:基于大语言模型的智能体已被广泛应用于个人助理领域,能够记忆用户消息中的信息并回应个人查询。然而,对其记忆能力的客观和自动化评估仍然缺乏,这主要归因于根据用户消息构建可靠问答对的挑战。在本文中,我们提出了MemSim,这是一个贝叶斯仿真器,旨在从生成的用户消息中自动构建可靠的问答对,同时保持其多样性和可扩展性。具体而言,我们引入了贝叶斯关系网络(BRNet)和因果生成机制,以减轻大语言模型幻觉对事实信息的影响,促进评估数据集的自动创建。基于MemSim,我们在日常生活场景中生成了一个名为MemDaily的数据集,并进行了大量实验以评估我们方法的有效性。我们还基于MemDaily数据集为评估基于大语言模型智能体中不同记忆机制提供了一个基准。
论文介绍
论文题目:Scaling Diffusion Transformers Efficiently via μP
作者:郑晨宇,张新雨,王榕甄,黄伟,田值,黄伟林,朱军,李崇轩
通讯作者:李崇轩
论文概述:扩散Transformer已成为视觉生成模型的基础架构,但其可扩展性受限于大规模超参数调优的高昂成本。近期提出的最大更新参数化(μP)方法在标准Transformer中实现了超参数从小型到大型语言模型的稳定迁移,显著降低了调优成本。然而,该方法能否适用于架构和目标函数均存在差异的扩散Transformer仍属未知。本研究将标准μP推广至扩散Transformer,并通过大规模实验验证其有效性。首先,我们严格证明了包括DiT、U-ViT、PixArt-α和MMDiT在内的主流扩散Transformer均与标准Transformer具有相同的μP特性,可直接应用现有μP方法论。基于此发现,我们系统论证了DiT-μP具备强大的超参数可迁移性——采用迁移学习率的DiT-XL-2-μP比原始DiT-XL-2实现2.9倍的加速收敛。最后,我们在文本到图像生成任务中验证μP的有效性:将PixArt-α从0.04B参数量扩展至0.61B,MMDiT从0.18B扩展至18B。两种情况下,采用μP的模型在显著降低调优成本的同时均超越基线性能——PixArt-α仅需单次训练5.5%的调优成本,MMDiT-18B仅消耗人类专家3%的调优资源。这些结果表明μP为扩散Transformer的规模化扩展提供了原则性且高效的框架。
论文介绍
论文题目:GUI-G1: Understanding R1-Zero-Like Training for Visual Grounding in GUI Agents
作者:周雨琦,戴孙浩,王帅,周凯文,贾庆林,徐君
通讯作者:王帅,徐君
论文概述:论文分析了R1-Zero强化学习范式在GUI视觉定位任务中的三大瓶颈——冗长推理链损害定位精度、奖励函数诱发“奖励黑客”、策略更新存在长度与难度偏差,并针对性提出“快速思考模板”压缩输出、“尺寸约束奖励函数”平衡命中与框体质量、以及“去归一化+难度加权”的策略优化机制。最终构建的轻量模型在仅17K训练样本下,在ScreenSpot和ScreenSpot-Pro基准上分别达到90.3%与37.1%的准确率,同时推理速度相较InfiGUI提升3倍,证明“少即是多”在GUI代理训练中切实可行。
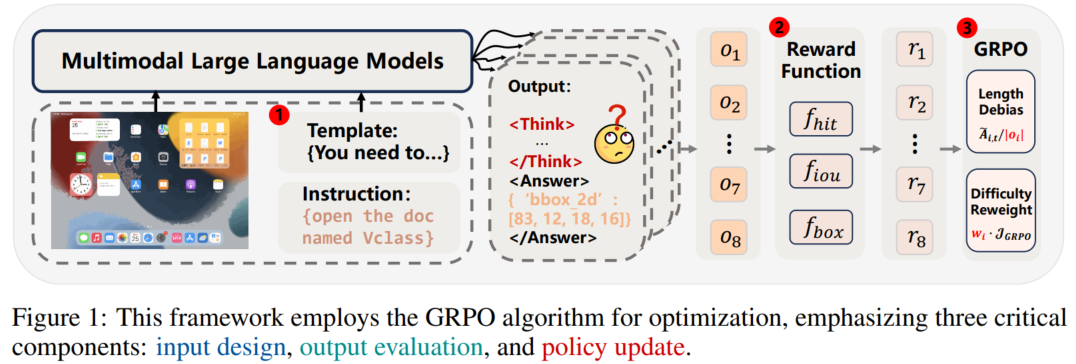
论文介绍
论文题目:Stability and Sharper Risk Bounds with Convergence Rate $1/n^2$
作者:朱博炜,李少杰,易鸣洋,刘勇
通讯作者:李少杰,刘勇
论文概述:既往研究证实,在强凸性、光滑性及损失函数Lipschitz连续等常见假设下,基于算法稳定性的强凸学习器最多能以高概率获得$O\left(\log (n)/n\right)$的过量风险界。我们证明,在相同假设下,至多可达到$O\left(\log^2(n)/n^2\right)$的速率。据我们所知,该分析也为非凸设定下基于梯度类方法的泛化间隙提供了最紧的高概率界。
论文介绍
论文题目:Counterfactual Reasoning for Steerable Pluralistic Value Alignment in Large Language Models
作者:郭翰泽*,姚菁*,周骁,矣晓沅,谢幸
通讯作者:周骁
论文概述:随着大语言模型(LLMs)逐渐服务于多元文化与人群,如何实现细粒度的价值对齐成为挑战。现有方法普遍存在两大问题:一是将多维价值视为独立存在,忽视其复杂依赖与优先级;二是缺乏对价值优先级的精确可控性,尤其是对弱势或稀有价值对齐目标。
我们提出COUPLE,一个基于结构因果模型(SCM)的多元价值对齐框架。该方法通过因果图建模价值维度之间的结构依赖与层级优先,并进一步刻画价值对下游行为的因果作用机制。在此基础上,COUPLE引入反事实推理,可在保持因果一致性的前提下,让LLM生成满足特定价值目标的输出。
实验结果显示,COUPLE在多种价值体系的数据集上显著优于现有对齐方法,不仅在处理复杂价值组合和优先级控制上更具鲁棒性,还提供了更强的可解释性。
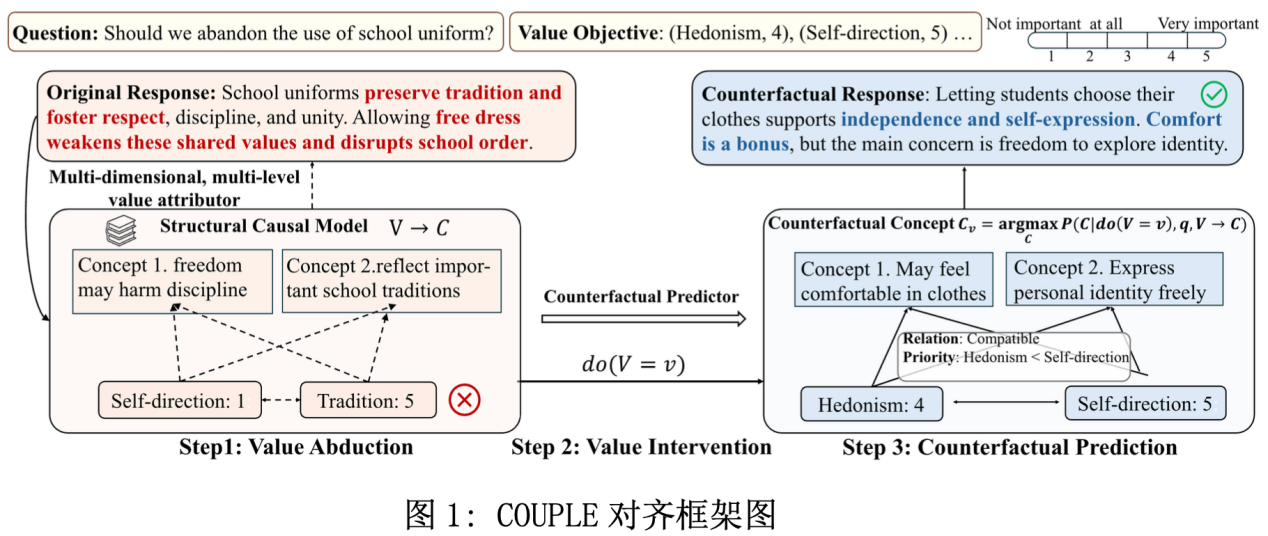
论文介绍
论文题目:MOF-BFN: Metal-Organic Frameworks Structure Prediction via Bayesian Flow Networks
作者:矫瑞,吴翰林,黄文炳,宋宇轩,欧阳亚文,荣钰,徐挺洋,王鹏举,周浩,马维英,刘菁菁,刘洋
通讯作者:黄文炳,周浩,刘洋
论文概述:金属有机框架(Metal-Organic Frameworks, MOFs)因其独特的性质——包括高比表面积和可调控的孔隙率——而受到广泛关注,并在催化、气体储存和药物递送等领域展现出巨大应用潜力。MOFs 的结构预测是一项具有挑战性的任务,因为这类框架本质上具有周期性和层级性,其整体结构由金属节点和有机连接体等基本单元拼装而成。为解决这一问题,我们提出了一种新型生成模型 MOF-BFN,基于贝叶斯流网络(Bayesian Flow Networks, BFNs)进行 MOF 结构预测。该模型在给定基本单元的局部几何信息的条件下,可以联合预测晶格参数以及晶胞内所有基本单元的位置和取向。具体而言,位置采用分数坐标系建模,从而自然地融入周期性;而取向则表示为单位四元数,并通过所提出的 Bingham BFN 从学习得到的 Bingham 分布中采样,从而实现了在四维单位超球面上的有效取向生成。实验结果表明,MOF-BFN 在多个任务中均达到了当前最先进的性能,包括结构预测、几何性质评估以及全新生成。这为复杂 MOF 材料的设计提供了一种有前景的工具。
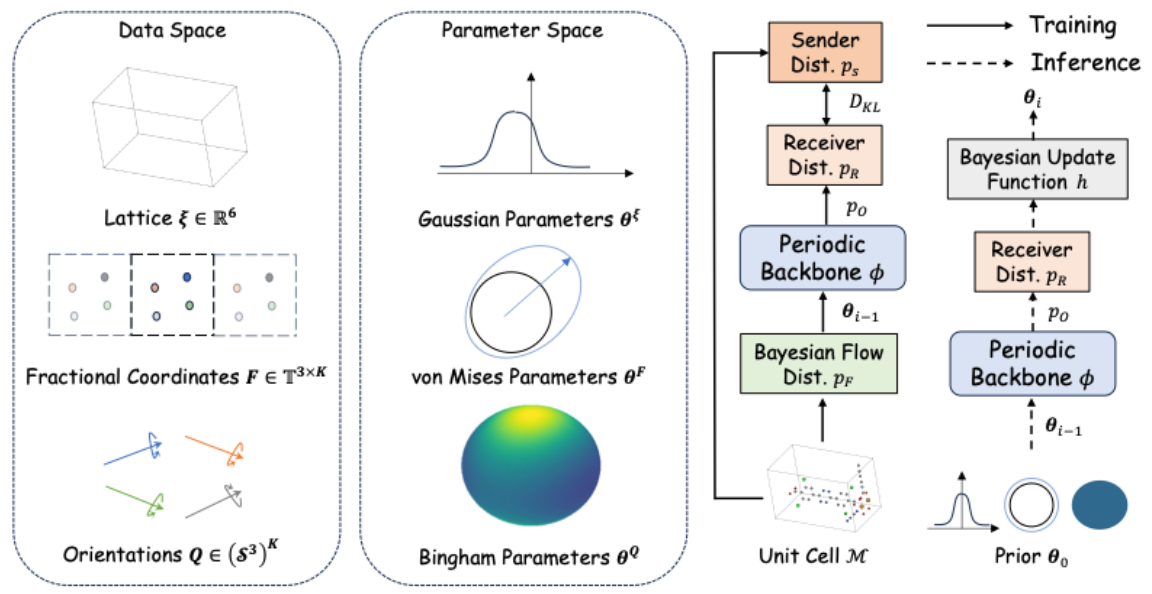
论文介绍
论文题目:Learning 3D Anisotropic Noise Distributions Improves Molecular Force Fields
作者:柳西贤,矫瑞,刘致远,刘语柔,刘洋,陆子恒,黄文炳,张阳,曹艺馨
通讯作者:刘致远,黄文炳
论文概述:坐标去噪因其在理论上与分子力场学习的紧密联系,已成为三维分子预训练中的一种有前景的方法。然而,现有的去噪方法依赖于过于简化的分子动力学假设,认为原子运动是各向同性且同方差的。为克服这些局限,我们提出了一种全新的去噪框架 AniDS:各向异性变分自编码器(Anisotropic Variational Autoencoder)用于三维分子去噪。AniDS 引入了一种结构感知的各向异性噪声生成器,能够为高斯噪声分布生成基于原子的完整协方差矩阵,从而更好地反映分子体系中方向性和结构上的差异。这些协方差通过原子对之间的相互作用计算而来,作为对各向同性基底的各向异性修正。我们的设计保证了生成的协方差矩阵在数学上是对称的、半正定的,并满足 SO(3) 等变性,同时具备更强的建模复杂分子动力学的能力。大量实验表明,AniDS 在 MD17 和 OC22 基准测试中显著优于此前的各向同性、同方差去噪模型以及其他领先方法,在力预测精度上分别取得了 8.9% 和 6.2% 的平均相对提升。进一步的晶体结构案例研究表明,AniDS 能够自适应地在化学键方向上抑制噪声,这与物理化学原理高度一致。
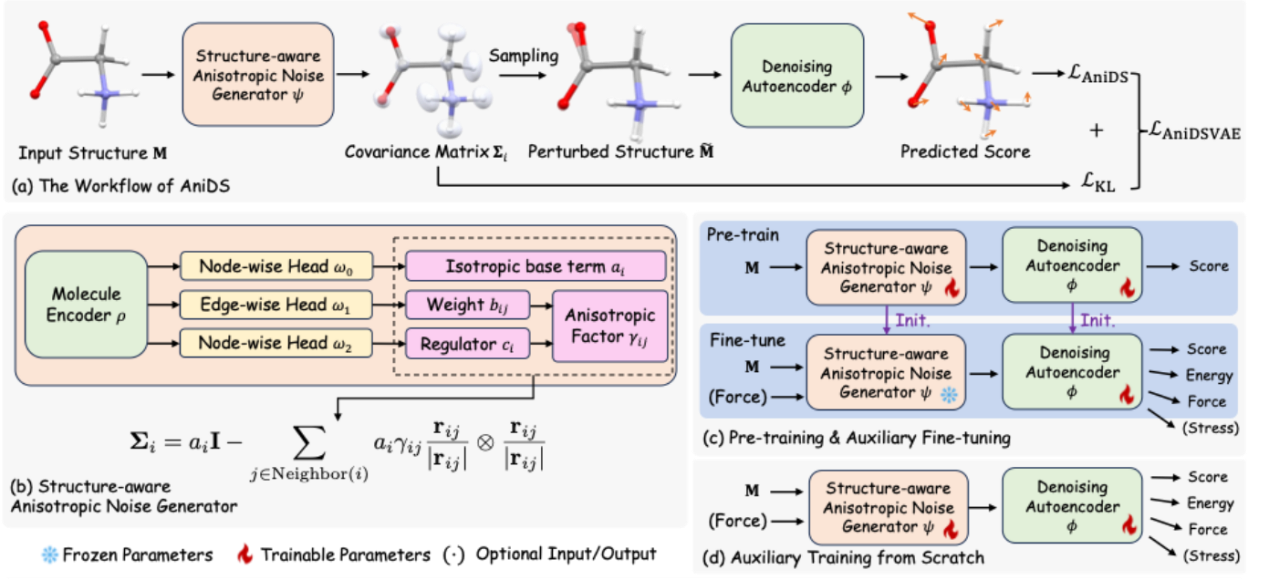
论文介绍
论文题目:MF-LLM: Simulating Population Decision Dynamics via a Mean-Field Large Language Model Framework
作者:米祈睿,杨梦月,于湘凝,赵祉瑜,邓程,安波,张海峰,陈旭,汪军
通讯作者:张海峰,陈旭,汪军
论文概述:模拟集体决策并不只是对个体行为的简单求和;它源于个体之间的动态交互。尽管大语言模型(LLMs)在社会仿真方面潜力巨大,但如何与真实世界数据实现定量对齐仍是关键挑战。为此,我们提出 Mean-Field LLM(MF-LLM) 框架,这是首个将均值场理论引入基于 LLM 的社会仿真的方法。MF-LLM 通过迭代过程同时建模个体与总体之间的双向交互:生成用于指导个体决策的群体信号,而个体决策又会反过来更新这些信号。这种相互作用产生了连贯的群体行为轨迹。为进一步提升与真实数据的一致性,我们提出 IB-Tune,一种受信息瓶颈原理启发的全新微调方法,在滤除冗余历史的同时,保留对未来行为最具预测性的群体信号。在真实社会数据集上的评估表明,相比于非均值场的基线方法,MF-LLM 将与人群分布的 KL 散度降低了 47%,从而实现更准确的趋势预测和更有效的干预规划。跨 7 个领域与 4 种 LLM 骨干模型的泛化结果显示,MF-LLM 为社会仿真提供了一个可扩展、高保真的基础。
论文介绍
论文题目:Irrational Complex Rotations Empower Low-bit Optimizers
作者:田震,赵鑫,文继荣
通讯作者:赵鑫
论文概述:论文提出了一种新型优化器状态压缩方法π-Quant。其核心思想是利用复数旋转与无理数的性质,将参数对映射为单一旋转角,从而精确地将存储规模减半。进一步通过角度量化,实现平均3.32-bit精度表示。该方法具备线性复杂度、误差更低和非均匀分布优势,能在保槙持模型精度的同时将优化器内存占用减少约40%,并在多项任务上超越现有低比特优化器。
论文介绍
论文题目:A Generalized Iterative Imputation Framework for Model Adaptation and Oracle Feature Utilization
作者:王浩,李正楠,陈智超,陈旭,何淑婷,刘广义,李昊轩,林宙辰
通讯作者:陈旭,李昊轩,林宙辰
论文概述:迭代插补是完成缺失数据的一种常用方法:它将每个特征依次视为目标变量,并利用其余特征来预测其缺失值。然而,现有迭代插补方法存在两个关键缺陷:(1) 模型错设:在不同特征上采用统一的参数化模型形式,与异质的数据生成过程相冲突;(2) 对 oracle 特征的利用不足:把所有特征都视为可能缺失,从而忽视了那些完全观测特征中蕴含的有价值信息。为此,我们提出核点插补(KPI),一个用于解决上述问题的双层优化框架。内层优化在再生核希尔伯特空间(RKHS)中为每个特征自适应地确定模型形式,以缓解模型错设;外层优化将 oracle 特征作为监督信号来精炼插补结果。大量真实数据集的实验表明,KPI 持续优于当前最先进的插补方法。
论文介绍
论文题目:TransDF: Time-Series Forecasting Needs Transformed Label Alignment
作者:王浩,潘黎铖,陈智超,陈旭,戴清阳,王磊,李昊轩,林宙辰
通讯作者:陈旭,李昊轩,林宙辰
论文概述:训练时间序列预测模型时,在设计有效的学习目标方面面临独特挑战。现有方法主要采用时间维的均方误差(MSE),但存在两大问题:(1)标签自相关,会使基于标签序列似然的估计产生偏差;(2)任务数量过多,且随预测视野增大而膨胀,导致优化更为复杂。为解决这些问题,我们提出了变换增强的直接预测方法 TransDF,将标签序列变换为去相关、且具有区分性重要性的若干成分。模型被训练去对齐最重要的成分,从而有效缓解标签自相关并减少任务量。大量实验表明,TransDF 取得了当前最先进的性能,并且可与多种预测模型兼容。
论文介绍
论文题目:Latent Retrieval Augmented Generation of Cross-Domain Protein Binders
作者:张子申,孔祥哲,黄文炳,刘洋
通讯作者:黄文炳,刘洋
论文概述:在药物发现中,设计能够特异性结合靶点的蛋白结合物,并生成真实且功能合理的相互作用模式,是一项根本性挑战。现有的基于结构的生成模型在生成具备充分合理性与可解释性的结合界面方面仍存在局限。在本文中,我们提出了一种新的框架 RADiAnce (Retrieval-Augmented Diffusion for Aligned interface),该方法利用已知的界面来引导新型结合物的设计。通过在统一的对比潜在空间中结合检索与生成,我们的模型能够高效识别给定结合位点的相关界面,并将其无缝整合到条件潜在扩散生成器中,从而实现跨领域的界面迁移。大量实验表明,RADiAnce 在多项指标上显著优于基线模型,包括结合亲和力、几何结构及相互作用的恢复。进一步的实验结果验证了跨领域泛化能力,表明从多样化领域(如肽类、抗体和蛋白片段)中检索界面能够提升在其他领域结合物生成的性能。本研究建立了一种新的蛋白结合物设计范式,成功地将检索知识与生成式人工智能相结合,为药物发现开辟了新的可能性。
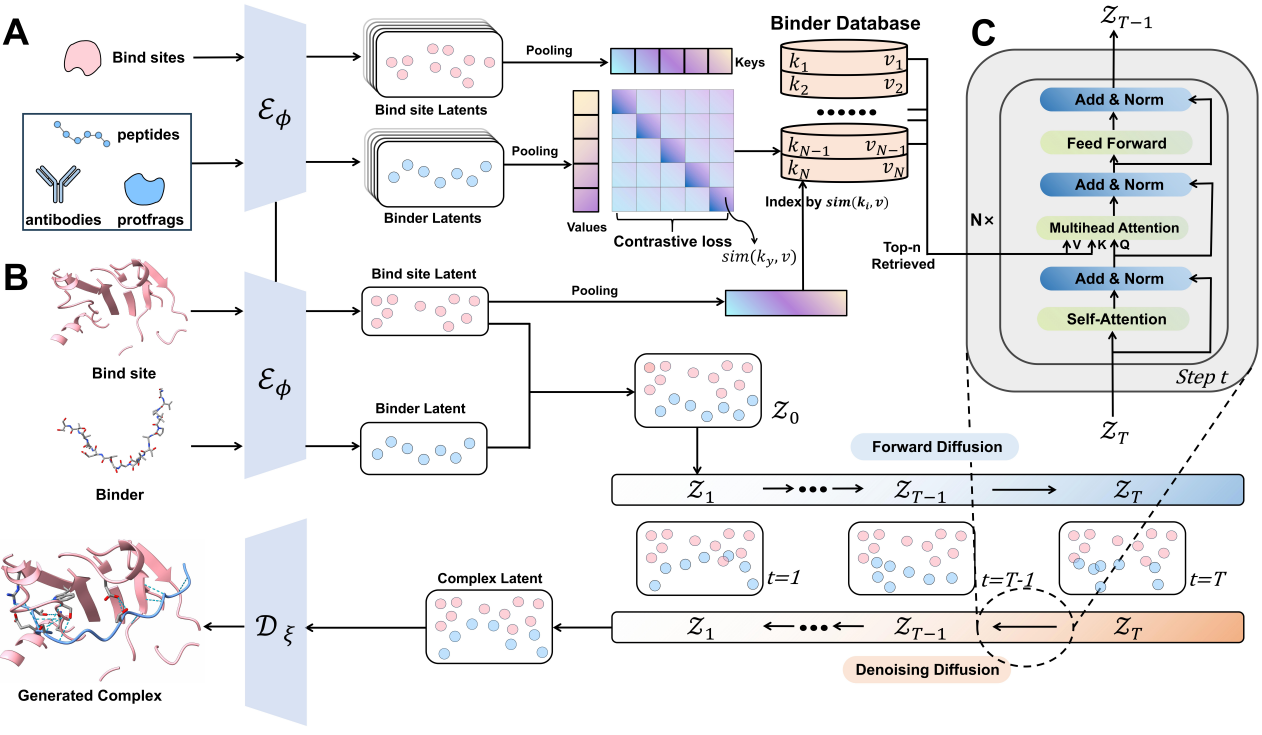
论文介绍
论文题目:SSTAG: Structure-Aware Self-Supervised Learning Method for Text-Attributed Graphs
作者:刘茹悦, 殷荣, 薄相振, 郝孝帅, 刘勇, 钟进文, 马灿, 王伟平
论文概述:大规模预训练模型彻底改变了自然语言处理(NLP)与计算机视觉(CV)领域,展现出卓越的跨领域泛化能力。然而在图学习领域,模型通常仅在单个图数据集上训练,这限制了其跨图结构与跨任务的知识迁移能力。该方法还高度依赖大量标注数据,在资源受限的场景下面临严峻挑战。与NLP和CV不同,图结构数据因其固有的异质性(如不同应用场景中领域特定的特征空间与结构多样性)而存在独特挑战。为应对这些挑战,我们提出面向文本属性图的结构感知自监督学习方法(SSTAG)。通过将文本作为图学习的统一表征媒介,SSTAG在大语言模型(LLM)的语义推理能力与图神经网络(GNN)的结构建模能力之间构建了桥梁。我们设计了双知识蒸馏框架,将LLM与GNN协同蒸馏至结构感知的多层感知机(MLP)中,从而提升大规模文本属性图的可扩展性。此外,引入内存存储机制,将典型图表征与内存存储库中的锚点对齐,整合不变性知识以增强模型泛化能力。大量实验表明,SSTAG在跨领域迁移学习任务中超越现有最优模型,具有卓越的可扩展性,并在保持竞争力的同时显著降低推理成本。
论文介绍
论文题目:HawkBench: Investigating Resilience of RAG Methods on Stratified Information-Seeking Tasks
作者:钱泓锦,刘政,高超,王岩开,连德富,窦志成
论文概述:在真实的信息检索场景中,用户的需求具有动态性与多样性,这要求 RAG 系统展现出适应性与韧性。为全面评估现有 RAG 方法的韧性,我们提出 HawkBench —— 一个人工标注的多领域基准,旨在对不同类别任务中 RAG 的表现进行严格考察。通过依据信息检索行为对任务进行分层,HawkBench 系统化地评估了 RAG 系统在多样化用户需求下的适应能力。与现有基准不同(它们大多集中在特定任务类型,尤其是事实型查询,并依赖于不一致的知识库),HawkBench 具有以下特点:1. 提供系统化的任务分层,覆盖范围广泛的查询类型,包括事实型与推理型任务;2. 融合跨领域语料于所有任务类型,以减少语料偏差;3. 采用严格标注,确保高质量评测。
HawkBench 共包含 1,600 条高质量测试样本,在领域与任务类型之间均匀分布。基于该基准,我们对具有代表性的 RAG 方法进行了评估,从答案质量与响应延迟两个方面分析其表现。研究结果表明,为提升 RAG 的通用性,亟需引入动态任务策略,结合决策制定、查询理解与全局知识把握。我们相信,HawkBench 将成为推动 RAG 方法韧性发展、实现通用型信息检索的重要基准。
论文介绍
论文题目:Chain-of-Retrieval Augmented Generation
作者:王亮,陈浩楠,杨南,黄小龙,窦志成,韦福如
论文概述:本文提出了一种训练 o1 类 RAG 模型的方法,该类模型能够在生成最终答案之前,逐步进行信息检索与推理。传统的 RAG 方法通常在生成之前只进行一次检索,这种单步检索在面对复杂查询时效果有限,因为初始检索结果往往并不完美。相比之下,我们的方法——CoRAG(Chain-of-Retrieval Augmented Generation,链式检索增强生成),使模型能够根据推理过程中不断演化的状态动态地重构查询。为有效训练 CoRAG,我们采用拒绝采样(rejection sampling)自动生成中间检索链,从而扩充现有仅提供最终正确答案的 RAG 数据集。在测试阶段,我们提出多种解码策略,通过控制检索链的长度和数量来灵活调整模型在测试时的计算量。在多个基准数据集上的实验结果表明,CoRAG 具有显著的效果提升,尤其是在多跳问答任务中,较强基线方法的 EM 分数提升超过 10 个百分点。在 KILT 基准上,CoRAG 在多种知识密集型任务中创造了新的最优性能。此外,我们还进行了系统的分析,以理解 CoRAG 的可扩展性特征,为未来研发更具事实性和可靠性的基础模型奠定了研究基础。
DB Track
论文介绍
论文题目:ICPC-Eval: Probing the Frontiers of LLM Reasoning with Competitive Programming Contests
作者:徐十一*,胡译文*,闵映乾,陈志朋,赵鑫,文继荣
通讯作者:赵鑫
论文概述:随着大型推理模型在复杂代码与推理任务上的显著进展,现有的基准测试(如 LiveCodeBench 和 CodeElo)已不足以评估大语言模型(LLMs)在真实竞赛环境中的编程能力。此外,目前常用的评估指标(如 Pass@K)也难以有效衡量推理模型的反思能力。为了解决这些挑战,我们提出了 ICPC-Eval ——一个顶级的竞赛编程基准测试,用于探索 LLM 推理能力的前沿。ICPC-Eval 收录了来自全球不同区域 11 场近期 ICPC 比赛中精心挑选的 118 道题目,并带来三方面的核心贡献:1. 逼真的 ICPC 竞赛场景:题型与难度分布与真实竞赛保持一致,充分还原比赛环境的挑战性;2. 鲁棒的测试用例生成方法与本地评测工具包:支持高效、准确的本地评测,提升评估的可复现性与实用性;3. 有效的测试时扩展评估指标 Refine@K:允许模型在执行反馈的基础上进行迭代修复,更好地衡量推理与反思能力。实验结果突显了评估复杂推理能力的重大挑战:即使是顶尖的推理模型(如 DeepSeek-R1),相比不具备推理能力的模型,往往需要依赖多轮代码反馈才能充分发挥其上下文推理潜力。此外,尽管代码生成领域取得了显著进步,这些模型的表现依然落后于顶尖的人类团队。我们在此开源该基准测试://github.com/RUCAIBox/ICPC-Eval
论文介绍
论文题目:MomentSeeker: A Task-Oriented Benchmark For Long-Video Moment Retrieval
作者:苑华莹*,倪鉴*,刘政,王岳泽,周俊杰,梁正阳,赵波,曹朝,窦志成,文继荣
通讯作者:窦志成
论文概述:准确识别长视频中的关键片段对于解决长视频理解任务具有重要意义。然而,现有基准测试存在明显局限性:要么受限于视频长度和任务多样性,要么仅关注端到端的整体性能,无法有效评估关键片段的定位准确性。为解决这一问题,我们提出了一个专为长视频片段检索设计的新型基准测试系统,MomentSeeker,其创新特性包括:首先,基于平均时长超过1200秒的多领域长视频构建,涵盖电影、异常监控、第一人称视角和体育等多样化场景;其次,设计了三层级的现实场景评估框架(全局层级、事件层级和对象层级),包含动作识别、物体定位和因果推理等常见任务;最后,支持文本查询、图像条件查询和视频条件查询等多模态检索方式。基于该基准测试,我们分别对生成式方法(直接使用多模态大语言模型)和检索式方法(结合视频检索器)进行了全面评估。实验表明,尽管最新长视频MLLMs和任务特异性微调技术有所进步,但长视频片段检索在准确性与效率方面仍面临重大挑战。目前我们已开源MomentSeeker数据集以及代码,以促进该领域的深入研究。

联系
- wmavfilm.net | 86-10-62511257
- 北京市海淀区中关村大街59号无码av影片
- copyright 无码av影片-免费线上av-日本高清av
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox